 Kuwa v0.4.0 已包含由 仨宇股份有限公司 貢獻的 Qualcomm NPU 支援,可大幅提升AI模型的生成速度,同時降低功耗。由於 Kuwa 無法在所有系統上可靠的偵測 NPU 是否可用,因此此功能預設未啟用。請按照以下步驟啟用 Qualcomm NPU 支援:
Kuwa v0.4.0 已包含由 仨宇股份有限公司 貢獻的 Qualcomm NPU 支援,可大幅提升AI模型的生成速度,同時降低功耗。由於 Kuwa 無法在所有系統上可靠的偵測 NPU 是否可用,因此此功能預設未啟用。請按照以下步驟啟用 Qualcomm NPU 支援:
在 Kuwa v0.4.0 中啟用 Qualcomm NPU 支援
· 閱讀時間約 2 分鐘

Yung-Hsiang Hu
Contributor
Kuwa v0.4.0 已包含由 仨宇股份有限公司 貢獻的 Qualcomm NPU 支援,可大幅提升AI模型的生成速度,同時降低功耗。由於 Kuwa 無法在所有系統上可靠的偵測 NPU 是否可用,因此此功能預設未啟用。請按照以下步驟啟用 Qualcomm NPU 支援:
Kuwa GenAI OS 是一個自由、開放、安全且注重隱私的開源人工智慧編導平台,我們提供友善的生成式人工智慧使用介面,讓使用者可以輕易的使用各種人工智慧模型、代理人與應用,也可以透過Kuwa的編導系統,以No-code或Low-code的方式輕易結合不同模型的長處,協助使用者快速完成更複雜的任務。 Kuwa提供多語言與多模型的開發與部署之整體解決方案,可以讓個人及各行各業在地端筆電、伺服器或雲端使用生成式AI、開發應用,或開Store商店、對外提供服務。
在台灣的西拉雅語中,Kuwa是人們聚會、討論與決策的公共集會場所。
Kuwa GenAI OS 的功能特色簡要說明如下:
Kuwa v0.3.4 提供了自訂第三方 API 金鑰功能,可以串接 Gemini 與 ChatGPT 以外的 API。
大多數使用者較難在地端運作參數量較大的模型,如 Llama3.1 70B 等大模型,
而 Groq 提供了免費雲端 API 讓使用者可以使用這些大模型。
本篇文章將說明如何在 Kuwa v0.3.4 上串接 Groq API。
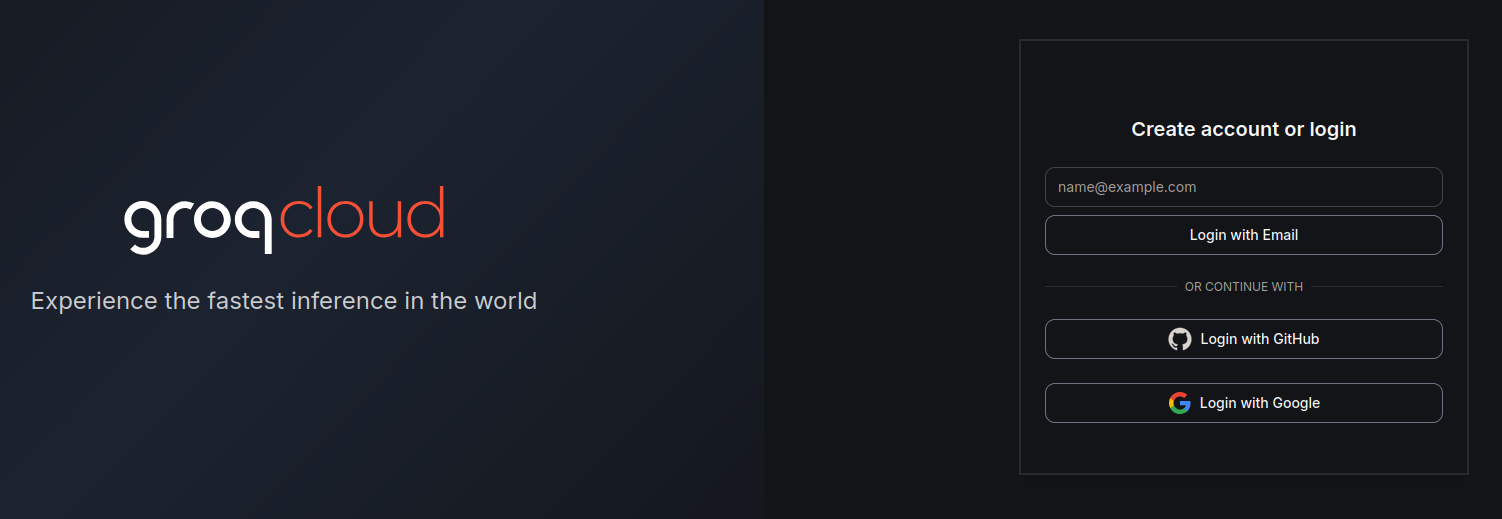
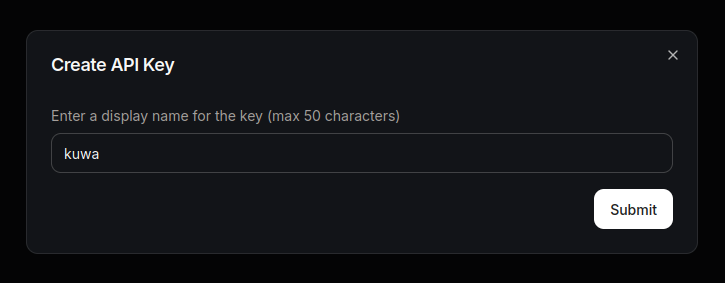
填入方便記憶的 API 金鑰名稱,並複製產生的 API 金鑰。
注意保存 API 金鑰,這個對話框消失後不會再顯示金鑰。
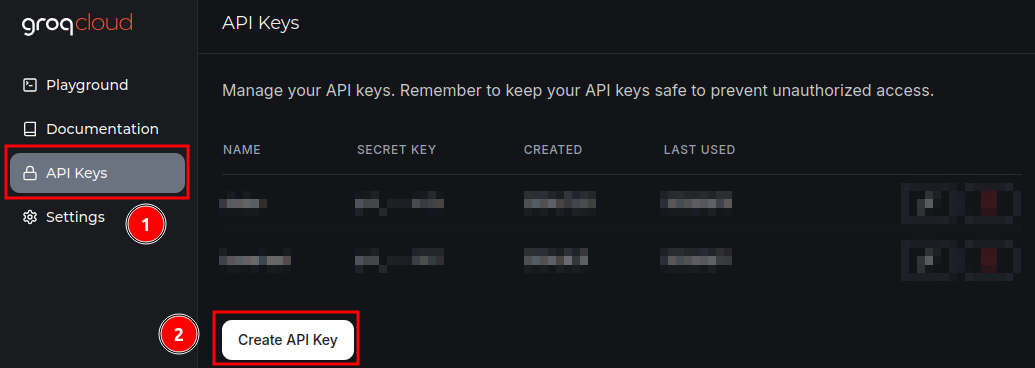

請在 "使用者設定 > API管理 > 自�訂第三方 API 金鑰" 中填入前一步申請的金鑰
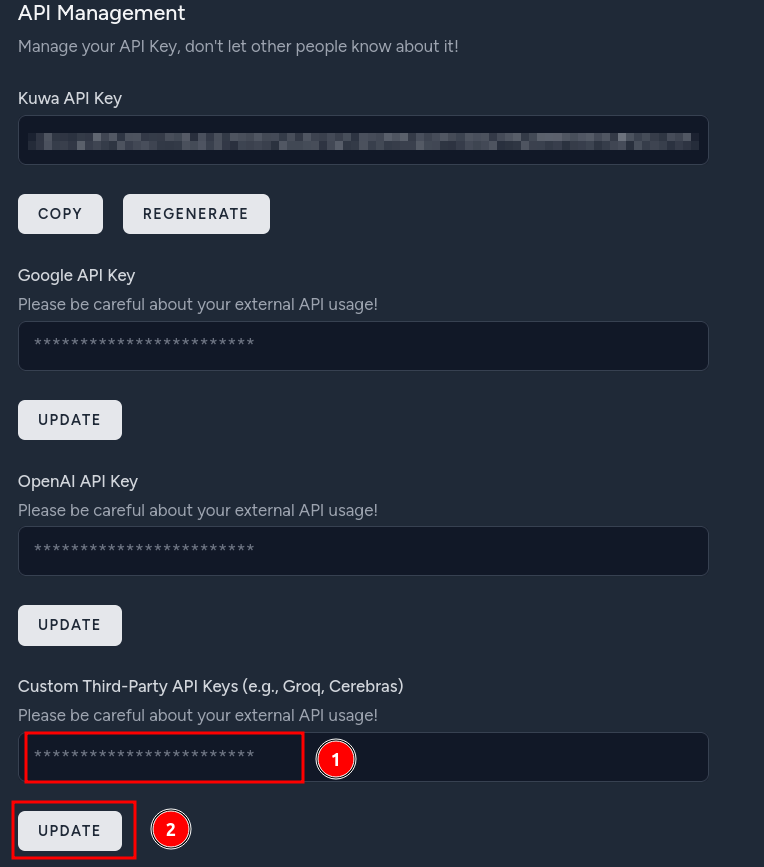
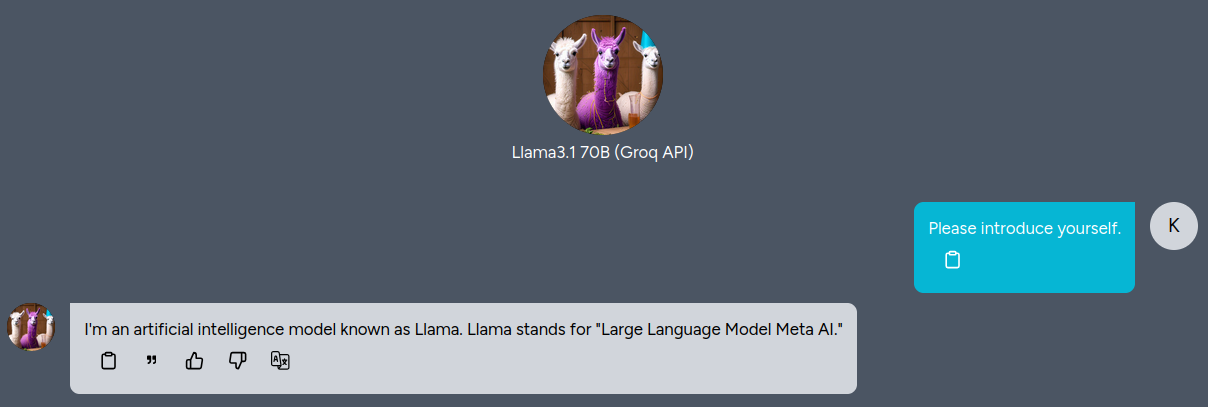
v0.3.4 預設有一名為 "Llama3.1 70B (Groq API)" 的 Bot
填入 Groq API 金鑰後即可使用該模型
台大曾亮軒同學和 NTU COOL 團隊於昨晚(7/17)釋出適合辨識台灣口音中文或是中英交雜音檔的 Cool-Whisper 模型,
Kuwa 透過簡單修改 Modelfile 即可直接套用。

2024/07/18 12:00 左右該模型因為隱私安全疑慮,暫時下架,
想使用這個模型的朋友可以持續關注該模型的 HuggingFace Hub,
待重新上架即可使用。
Kuwa 的 RAG 應用 (DocQA/WebQA/DatabaseQA/SearchQA) 從 v0.3.1 版本起支援透過 Bot 的 modelfile 自訂進階參數, 可以讓單個 Executor 虛擬化成多個 RAG 應用,詳細參數說明及範例如下。
以下參數內容為 v0.3.1 RAG應用的預設值。
PARAMETER retriever_embedding_model "thenlper/gte-base-zh" # embedding model名稱
PARAMETER retriever_mmr_fetch_k 12 # MMR前取幾個chunk
PARAMETER retriever_mmr_k 6 # MMR取幾個chunk
PARAMETER retriever_chunk_size 512 # 每個chunk的長度,以字元為單位 (DatabaseQA不受限制)
PARAMETER retriever_chunk_overlap 128 # chunk間的交疊長度,以字元為單位 (DatabaseQA不受限制)
PARAMETER generator_model None # 指定哪個模型回答,None表示自動選擇
PARAMETER generator_limit 3072 # 整個prompt的長度限制,以字元為單位
PARAMETER display_hide_ref False # 不顯示參考資料
PARAMETER crawler_user_agent "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36" # 爬蟲的UA字串
PARAMETER search_advanced_params "" # 進階搜尋參數 (SearchQA專用)
PARAMETER search_num_url 3 # 取用幾個搜尋結果[1~10] (SearchQA專用)
PARAMETER retriever_database None # Executor本機的向量資料庫路徑
假如要建立一個 DatabaseQA 知識庫並指定模型回答,可以建立一個 Bot,
基底模型選擇 DocQA,並填入以下 Modelfile。
PARAMETER generator_model "model_access_code" # 指定哪個模型回答,None表示自動選擇
PARAMETER generator_limit 3072 # 整個prompt的長度限制,以字元為單位
PARAMETER retriever_database "/path/to/local/database/on/executor" # Executor本機的向量資料庫�路徑
Kuwa 設計上支援串接各種非 LLM 的 Tool,最簡單的 Tool 可以參考 src/executor/debug.py,
以下是內容說明。
import os
import sys
import asyncio
import logging
import json
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
from kuwa.executor import LLMExecutor, Modelfile
logger = logging.getLogger(__name__)
class DebugExecutor(LLMExecutor):
def __init__(self):
super().__init__()
def extend_arguments(self, parser):
"""
Override this method to add custom command-line arguments.
"""
parser.add_argument('--delay', type=float, default=0.02, help='Inter-token delay')
def setup(self):
self.stop = False
async def llm_compute(self, history: list[dict], modelfile:Modelfile):
"""
Responsible for handling the requests, the input is chat history (in
OpenAI format) and parsed Modelfile (you can refer to
`genai-os/src/executor/src/kuwa/executor/modelfile.py`), it will return an
Asynchronous Generators to represent the output stream.
"""
try:
self.stop = False
for i in "".join([i['content'] for i in history]).strip():
yield i
if self.stop:
self.stop = False
break
await asyncio.sleep(modelfile.parameters.get("llm_delay", self.args.delay))
except Exception as e:
logger.exception("Error occurs during generation.")
yield str(e)
finally:
logger.debug("finished")
async def abort(self):
"""
This method is invoked when the user presses the interrupt generation button.
"""
self.stop = True
logger.debug("aborted")
return "Aborted"
if __name__ == "__main__":
executor = DebugExecutor()
executor.run()
Kuwa GenAI OS 是一個自由、開放、安全且注重隱私的開源系統,提供友善的生成式人工智慧使用介面,以及支援快速開發大語言模型應用的新世代生成式人工智慧編導系統。 Kuwa提�供多語言與多模型的開發與部署之整體解決方案,可以讓個人及各行各業在地端筆電、伺服器或雲端使用生成式AI、開發應用,或開Store商店、對外提供服務。
Kuwa GenAI OS 的簡要說明如下:

Kuwa v0.3.1 新增了基於 Stable Diffusion 圖片生成模型的 Kuwa Painter,
可以輸入一段文字產生圖片,或是上傳一張圖片並搭上一段文字產生圖片。

Kuwa v0.3.1 初步支援了常見的視覺語言模型 (VLM), 這類模型不但可以輸入文字,還可以輸入圖片,並根據圖片內容回應使用者的指令。 本篇教學將帶您初步建立與使用 VLM。
Kuwa v0.3.1 加入了基於 Whisper 語音辨識模型的 Kuwa Speech Recognizer, 可以透過上傳錄音檔來產生逐字稿,支援時間戳記以及語者標示。
預設使用 Whisper medium 模型並關閉語者標示功能,若跑在GPU上所消耗 VRAM 如下表所示。
| 模型名稱 | 參數量 | VRAM需求 | 相對辨識速度 |
|---|---|---|---|
| tiny | 39 M | ~1 GB | ~32x |
| base | 74 M | ~1 GB | ~16x |
| small | 244 M | ~2 GB | ~6x |
| medium | 769 M | ~5 GB | ~2x |
| large | 1550 M | ~10 GB | 1x |
| pyannote/speaker-diarization-3.1 (語者辨識) | - | ~3GB | - |